
Nội dung bài viết này sẽ xoay quanh về các thuật ngữ liên quan đến cào (crawl) dữ liệu từ các trang web. Các kỹ thuật và thao tác liên quan cũng như kiến thức cần có để thực hiện.
I. Giới thiệu
Một web crawler, còn được gọi là spider hoặc web spider, là một loại phần mềm tự động duyệt qua trang web và thu thập thông tin từ các trang web đó. Chúng hoạt động bằng cách đi từ liên kết này sang liên kết khác trên trang web, tự động thu thập dữ liệu trên mỗi trang mà chúng truy cập.
Các web crawler thường được sử dụng cho mục đích như thu thập thông tin, tạo bản đồ của trang web (web indexing) để tìm kiếm trên web, kiểm tra sự tồn tại của các liên kết hoặc tìm hiểu về cấu trúc của một trang web. Các công cụ tìm kiếm như Google sử dụng web crawler để thu thập dữ liệu từ các trang web trên Internet và cập nhật cơ sở dữ liệu của họ để cung cấp kết quả tìm kiếm cho người dùng.
Web crawler thường phải tuân thủ các quy tắc về robots.txt của trang web mà chúng truy cập để xác định xem chúng có được phép thu thập dữ liệu từ trang web đó hay không. Ngoài ra, việc quản lý tốc độ truy cập của web crawler là một vấn đề quan trọng để tránh gây ra quá tải cho các trang web mà chúng truy cập.
Trong phạm vi bài viết này, web crawl có thể hiểu là việc tải dữ liệu từ 1 trang web để thống kê, tổng hợp và tối ưu thời gian thực hiện nhất. Hiểu nôm na, bạn có 100 trang (page), mỗi trang 100 dòng dữ liệu, nhiệm vụ làm sao để lấy hết 100 trang dữ liệu đấy và nhập vào 1 file EXCEL duy nhất.
II. Thực hành
Hiện nay, JSON được sử dụng phổ biến để truyền tải dữ liệu giữa máy chủ và trình duyệt web. Điều này có thể là dữ liệu từ cơ sở dữ liệu, dữ liệu từ các API hoặc bất kỳ nguồn dữ liệu nào khác. JSON là một định dạng dữ liệu rất phổ biến và linh hoạt, cho phép dễ dàng truyền tải dữ liệu qua mạng.
Để đơn giản quá trình crawl dữ liệu các trang web có truyền tải dữ liệu bằng JSON, chúng ta có thể thực hiện tạo các yêu cầu để lấy dữ liệu JSON từ API
Để tải JSON từ một trang web sử dụng kỹ thuật web crawler, bạn có thể thực hiện các bước sau:
Bước 1: Xác định cấu trúc URL của các yêu cầu JSON:
Trang web có thể sử dụng các yêu cầu AJAX hoặc RESTful API để truy xuất dữ liệu dưới dạng JSON. Bạn cần phân tích cấu trúc URL của các yêu cầu này để xác định cách truy cập dữ liệu JSON. Đối với việc này, có thể sử dụng công cụ Dev Tool (F12) được trang bị sẵn trên các trình duyệt
Ví dụ cần tải tất cả giao dịch trên website https://tomoscan.io/txs
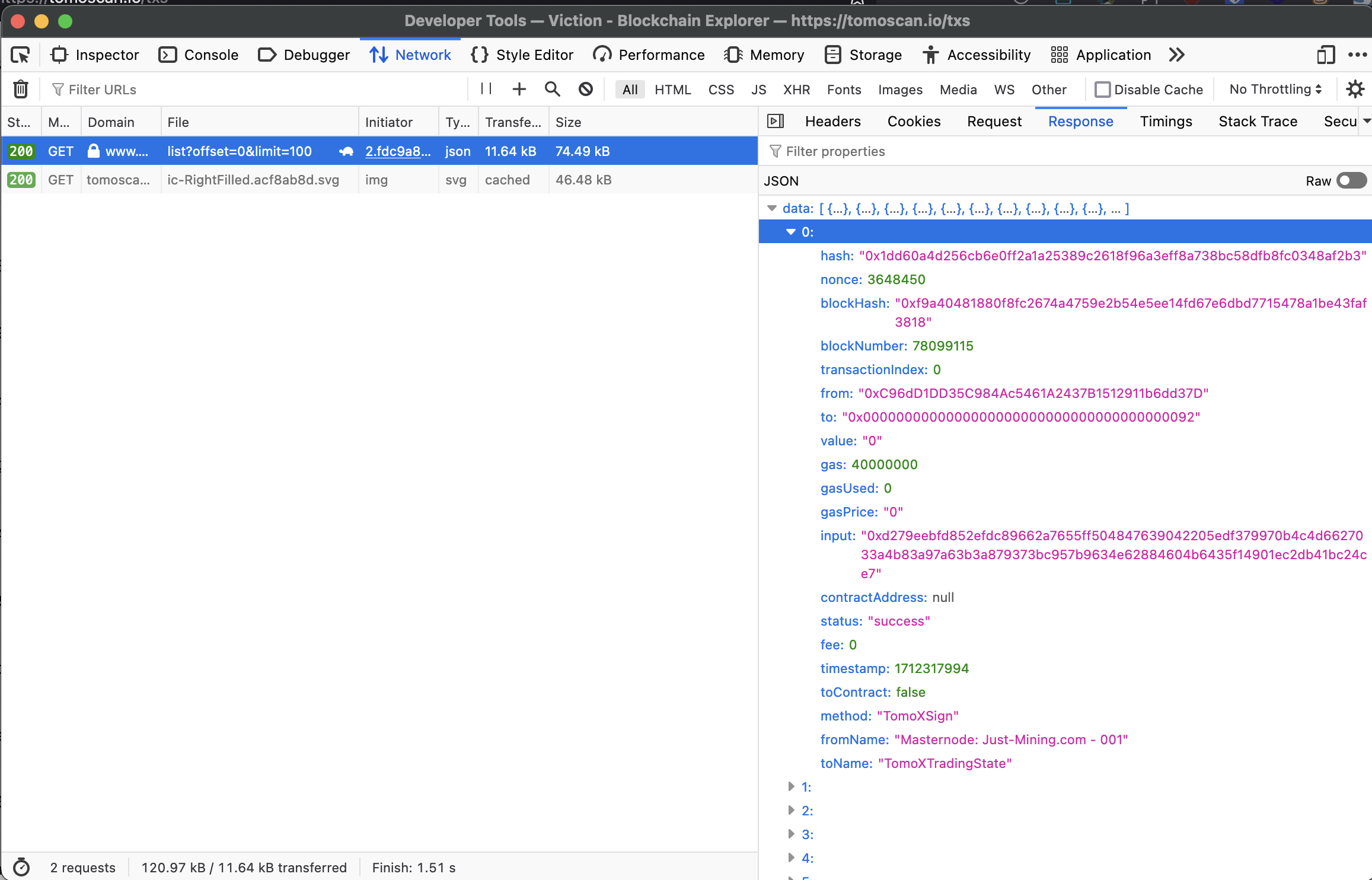
Chúng ta sử dụng công cụ F12 để tìm xem request nào là request lấy dữ liệu JSON từ server.
Bước 2: Xây dựng web crawler
Sử dụng ngôn ngữ lập trình như Python và các thư viện như requests và BeautifulSoup, bạn có thể viết một web crawler để duyệt qua các trang web và tìm kiếm các liên kết đến các yêu cầu JSON.
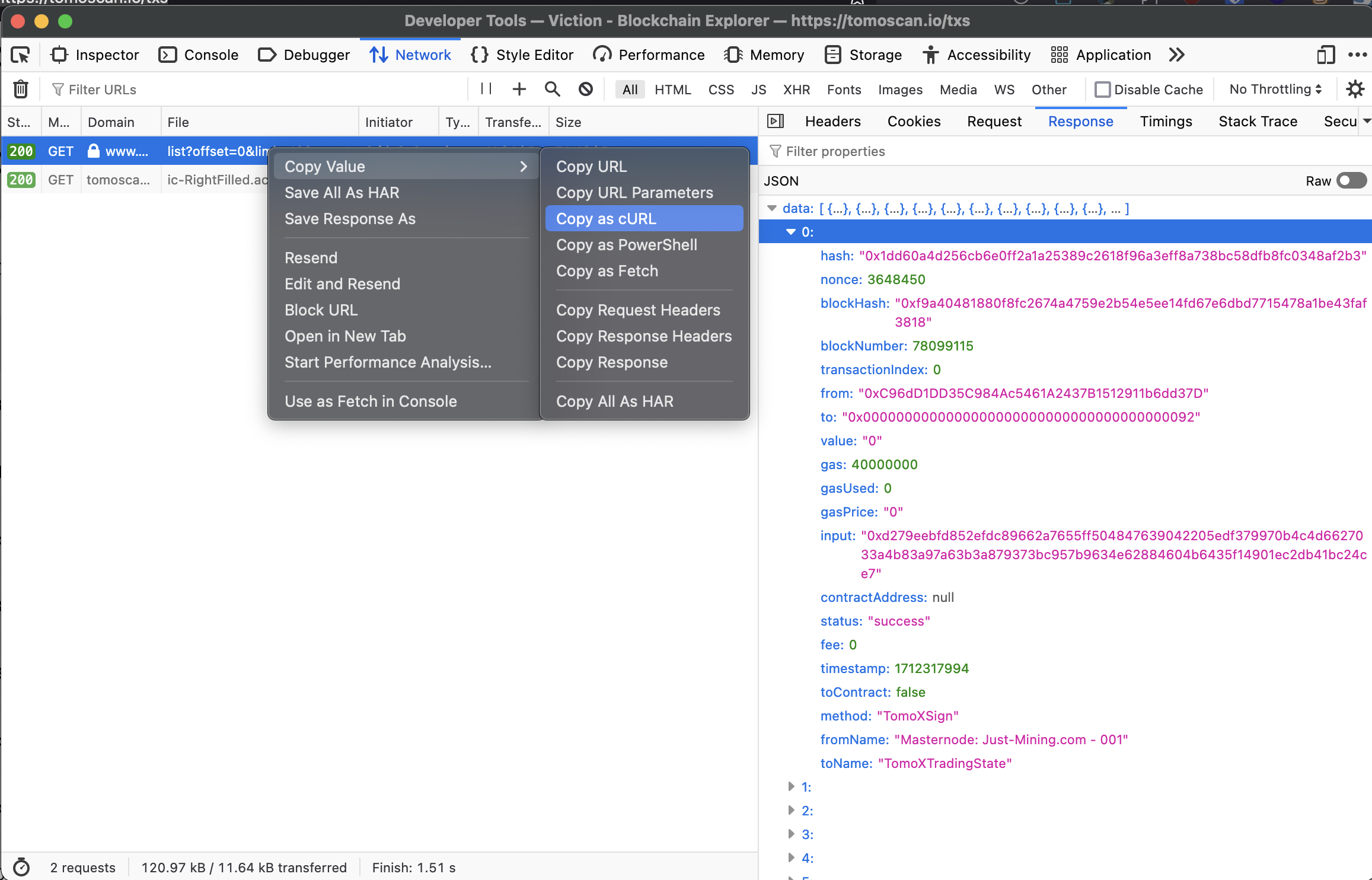
Ví dụ: Tiến hành sử dụng công cụ F12 để copy request dưới dạng cURL.
Bước 3: Gửi yêu cầu HTTP và tải JSON: Khi bạn đã xác định được URL của các yêu cầu JSON, bạn có thể sử dụng thư viện requests để gửi yêu cầu HTTP và tải JSON từ các trang web. Sau đó, bạn có thể lưu dữ liệu JSON vào tệp hoặc thực hiện các xử lý tiếp theo.
Ví dụ:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:124.0) Gecko/20100101 Firefox/124.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'en-US,en;q=0.5',
# 'Accept-Encoding': 'gzip, deflate, br',
'Origin': 'https://tomoscan.io',
'DNT': '1',
'Connection': 'keep-alive',
'Referer': 'https://tomoscan.io/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
}
params = {
'offset': '0',
'limit': '100',
}
response = requests.get('https://www.vicscan.xyz/api/transaction/list', params=params, headers=headers)
print(response.text)
Như vậy, sau khi chạy code Python trên sẽ thực hiện request đến API và lấy dữ liệu
III. Kiến thức liên quan
Để thực hiện và chạy được code như trên. Bạn cần trang bị cho bản thân:
- 1 chiếc máy tính chạy Windows, MacOS hay Ubuntu,... đều được
- Kiến thức cơ bản về Python
- Kiến thức cơ bản về Web (không cần code web, chỉ cần hiểu sơ về nguyên lý hoạt động, kiến thức HTML cơ bản)
Để học về Python thì hiển nhiên mọi người phải biết cách cài Python trước. Và mình nghĩ rằng mọi người có thể tham khảo video này
Khi mọi người đọc hiểu được đoạn code ở trên, thì mọi người đã làm được công việc crawl dữ liệu rồi. Và hiển nhiên, lập trình cũng như viết một bài văn, bạn sẽ căn cứ nhu cầu, điều kiện cụ thể mà thực hiện để phù hợp.
Bài viết này sẽ không đi vào chi tiết nhiều về kỹ thuật, mà sẽ là sự gợi mở nguồn cảm hứng để mọi người tìm hiểu về kỹ thuật liên quan và áp dụng vào công việc của bản thân.